
Why would you use local AI?
Using AI models locally offers several benefits. Data privacy is a key reason – your data remains on your computer, preventing it from being sent to external servers. This can be important for sensitive information. Company policies might also restrict the use of cloud-based AI services.
So if you're looking to ditch OpenAI/Google/Anthropic etc. and have never ran a model locally before, you're in the right place. This article is for people with:
- zero or close-to-none ML experience
- some software engineering / devops experience
The simplest way
Just download LM Studio or Ollama. I recommend the first one, since it's an all-in-one package, meanwhile Ollama is only a backend and a CLI.
For the longest time I didn't even feel like trying Ollama since to use it practically you need Open WebUI, which is only distributed through pip and is also a bit too bloated for basic exploration. But I did find Hollama which is perfect for a single user.
Here's what LM Studio looks like:
Just load the app, pick a model, open the chat tab and you're good to go!
It's that simple.
But running a model locally on your machine is likely not good enough for any software project. We'll need a dedicated LLM server for that. Before we dive any deeper, we must first establish a few concepts.
Model size and quantization
In order to navigate the model landscape, we need to understand a few concepts:
-
Model size: This refers to the number of parameters within the model (often measured in billions). Larger models (e.g., 70B parameters) generally exhibit improved performance, particularly in complex reasoning tasks, but demand significantly more computational resources (RAM, VRAM).
-
Context size: Context size: This refers to the maximum amount of text the model can consider at once when generating a response. It's measured in "tokens," which are roughly equivalent to words or parts of words. Larger context sizes enable more coherent conversations and the ability to process longer documents, but require more RAM.
-
Quantization: This technique reduces model size and improves inference speed by representing weights and activations with lower-precision data types (e.g., int8, int4 instead of float16 or float32). It introduces a trade-off between memory footprint, speed, and accuracy. Methods like GPTQ and AWQ further optimize quantization for minimal performance degradation.
Let's focus on Model size and Quantization, as these are the most important when you're picking a model. These two determine your memory requirements, which can be simplified to this equation:
Memory required = (Model size + Context size) / Quantization
Any ML engineer will tell you that this grossly incorrect, however for our basic exploration purposes this is good enough. (You'll learn about KV cache eventually anyway).
When it comes to quantization, it's just too good. You should always be running quantized models. Have a look at this performance comparison for Qwen2.5:
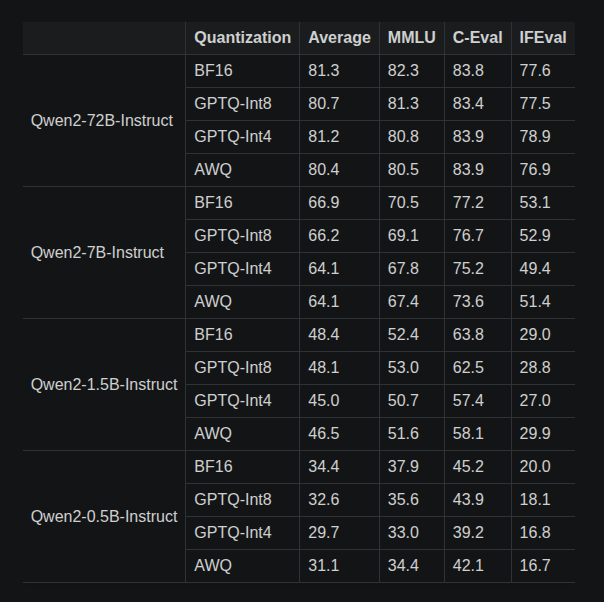
The 1st column is the LLM used. The 3 rightmost columns are benchmark results used to measure LLM performance. As you can see, there is little to no degradation in quality when using quantized versions, yet there are massive memory savings.
Always use quants.
Quantization greatly reduces the memory required while maintaining the quality
Example
Let's look at a sample model card:
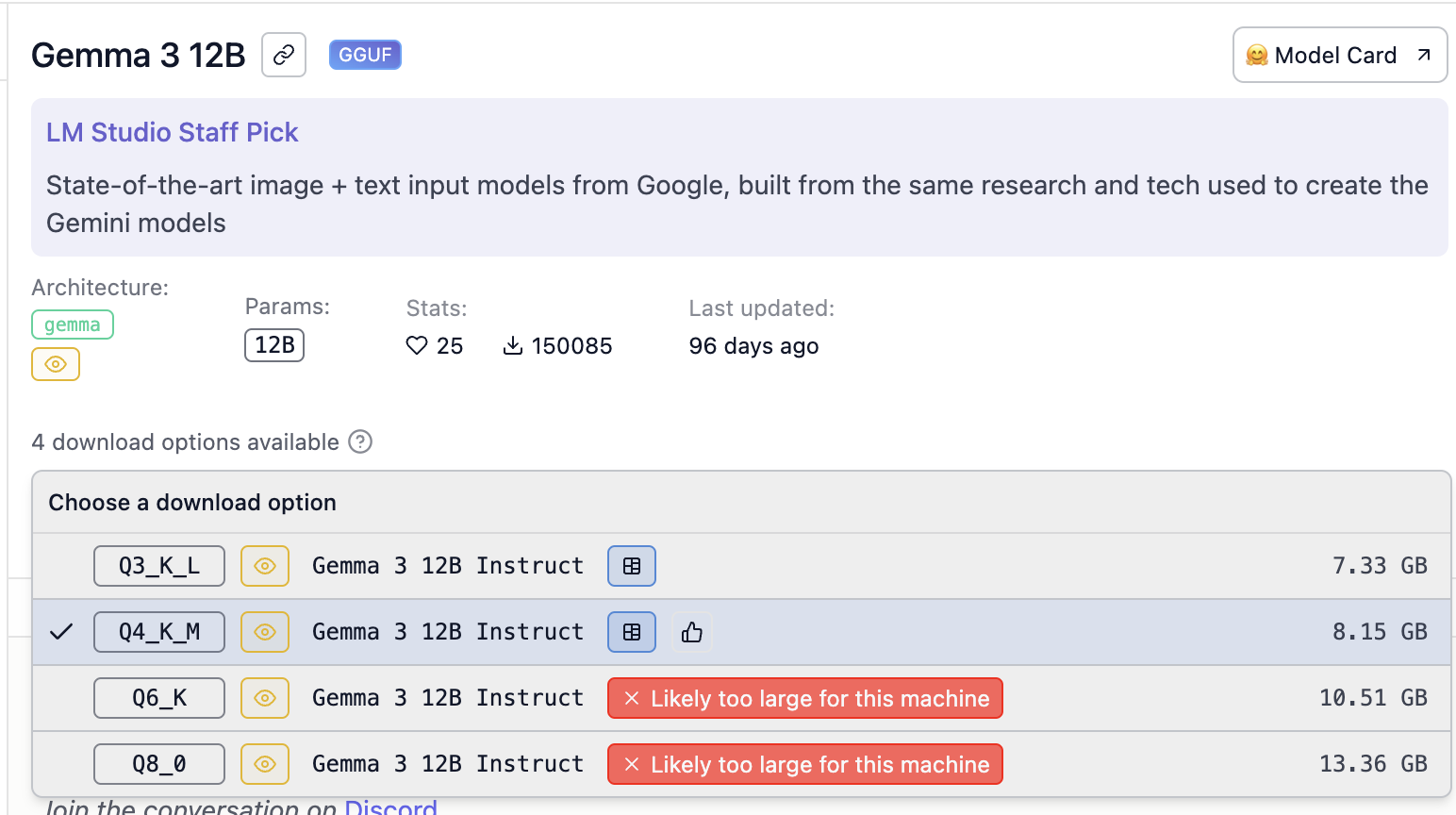
- Gemma 3 is the base model
- 12B is the base model size
- Q4_K_M is the quantization level
LM Studio also shows us what model size is acceptable for our hardware, which is quite neat.
Picking a model for your use case
Up until recently, you had to go for the big guys to get quality results - ex. Llama 3.3 70B. These models required massive hardware investments.
Thankfully, nowadays we no longer need to spend a ton of cash to create a powerful setup. Models are advancing at an absolutely astonishing speed. What used to require a 70B model, now can be done with a 7B model.
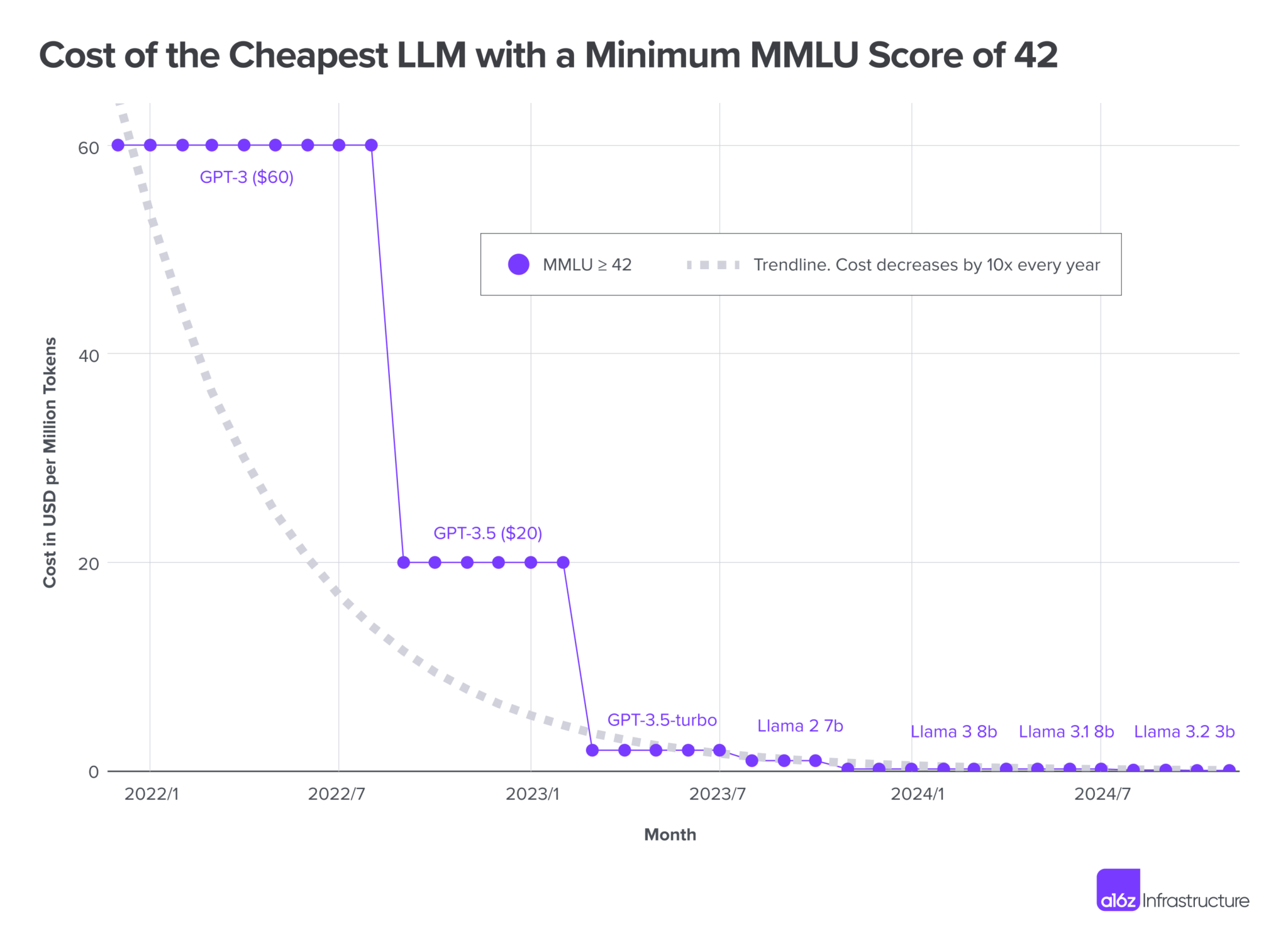
What you see here is the decrease in cost of running an LLM with comparable performance. This equation is also true in regards to model size, as seen on the chart (newer 3B model having the same quality as previous 7B model). This chart is almost a year old now, but the principle still holds true.
Newer, smaller models outperform older, larger models
We have benchmarks which measure specific model capabilities in certain areas like instruction following, math, creative writing and so on, and these are a great place to start. Unfortunately, Goodhart's Law has kicked in and companies started to optimize LLMs for benchmarks, not real-world use. Take benchmark results with a grain of salt.
With that said, you most likely came here looking for some recommendations, so here are some models which are simply really good:
- Mistral Small 3.1
- Gemma 3
- Qwen 3
Each of these are great at any size. It's debatable what is the minimum usable size of an LLM for complex tasks, supposedly even Qwen3 0.6B, which is small enough to run in browsers is already pretty capable. We'll talk more about model sizing in the next section.
Keep in mind that this is the situation in June 2025 - in 3-6 months time, the go-to models will likely be completely different.
Picking the hardware
We also need to make sure that we have the hardware needed to run the model we're looking at. We've got two options here:
- We can either build a GPU-based setup
- ...or use one of the newer dedicated unified architecture systems (Apple M chips, Ryzen AI Max)
In both cases, we need to look at the total amount of memory, which, as we've already discussed, determines how large of a model we can run, as well as memory bandwidth.
Memory bandwidth determines how fast the models will run
This is where things get tricky, as we either have small VRAM and lots of bandwidth (Dedicated GPUs), or lots of VRAM and small bandwidth (CPU setup).
These are some of the hardware choices I'd consider if I were to build an LLM server currently:
| Device | Bandwidth (GB/s) | Memory Amount | MSRP (USD) |
|---|---|---|---|
| Nvidia RTX 3090 | 936 GB/s | 24 GB | $1,000 |
| Nvidia RTX 5090 | 1792 GB/s | 32 GB | $2,000 |
| Apple M4 Pro | 273 GB/s | 64 GB | $1,999 (Mac mini base) |
| Apple M3 Ultra | 819 GB/s | 96 GB | $3,999 (Mac Studio base) |
| AMD Ryzen™ AI Max+ 395 --EVO-X2 AI Mini PC | 256 GB/s | 128 GB | $2,000 |
Now, how do I know which option I should go for?
If you have the cash for it, just go for RTX cards. They're the most versatile, you can use them for other ML stuff thanks to CUDA, they have the best support. You can use multiple ones, but it gets problematic quite fast due to power requirements, heat etc. And the cards themselves aren't exactly cheap. If you do stack multiple cards in a single PC & run this at load, you better have some industrial cooling setup, as you're looking at 1000W+ of noise and heat.
Beside the cost, you'll most likely have to deal with a much smaller context size.
If you want to run large models / need large context, go for CPU-based setup with lots of VRAM. Sure, it won't run as fast as on a GPU-based setup, but the system will stably & emit significantly less heat. Even though the requests will not run as fast, you will be able to support more traffic thanks to all that memory. If you're building a system for some internal company LLM setup, this is what I'd go for.
Running the models
If possible, just use vLLM. It's the largest and most mature LLM runtime, however unfortunately it only supports dedicated GPUs. If you're building a CPU-based system, you'll have to stick with Ollama.
So let's say we have 32GB VRAM available. You can of course just pick the largest model available that fits into the memory, but that will limit you to processing 1 request at the same time.
So instead of running Gemma 27B, we might go for running Gemma3 7B in order to support multiple requests.
It all depends on your use case.
The model execution is not the difficult part, it's the parameter tuning and picking the right setup for your needs. Just have a look at the argument list for vLLM.
I won't dive into specific commands here, as there's already plenty of content out there
How do I know how fast a model will run?
There are a lot of variables at play, and the numbers above should give you a rough estimate, but it's hard to estimate how fast a model will run. Model, quants, runtime, request amount, system load all play a factor here. Your best bet is either renting the hardware (I recommend vast.ai for quick experimentation) or searching for similar setups. (ex. "RTX 4090 LLM inference speed").
Summary
This is a very shallow exploration of the local LLM landscape, each of the topics here deserves a dedicated deep-dive. I just wanted to share my learnings and help others that are looking to venture out into the wilderness of local LLMs. This article should be a gateway that will allow you to dive deeper on your own, and the best place to do so is /r/LocalLLaMA.
Shameless plug: We're building an open-source Local AI-first platform for document processing, check it out if you're interested!